
One of the pain points we face with remote development is having to go through few extra hops to get to our virtual dev boxes. Many of us uses Azure VMs for development (in addition to local machines) and our security policy is to lock down all VMs to our Microsoft corporate network.
So to ssh or rdp into an Azure VM for development, we first connect over VPN to corporate network, then use a corpnet machine to then login to the VMs. That is painful and more so now when we are working remotely.
This is where the newly announced Visual Studio Codespaces come in. Basically it is a hosted vscode in the cloud. It runs beautifully inside a browser and best of all comes with full access to the linux shell underneath. Since it is run as a service and secured by the Microsoft team building it, we can simply use it from a browser on any machine (obviously over two-factor authentication).
At the time of writing this post, the cost is around $0.17 per hour for 4 core/8GB which brings the price to around $122 max for the whole month. Codespaces also has a snooze feature. I use snooze after one hour of no usage. This does mean additional startup time when you next login, but saves even more money. In between snooze the state of the box is retained.
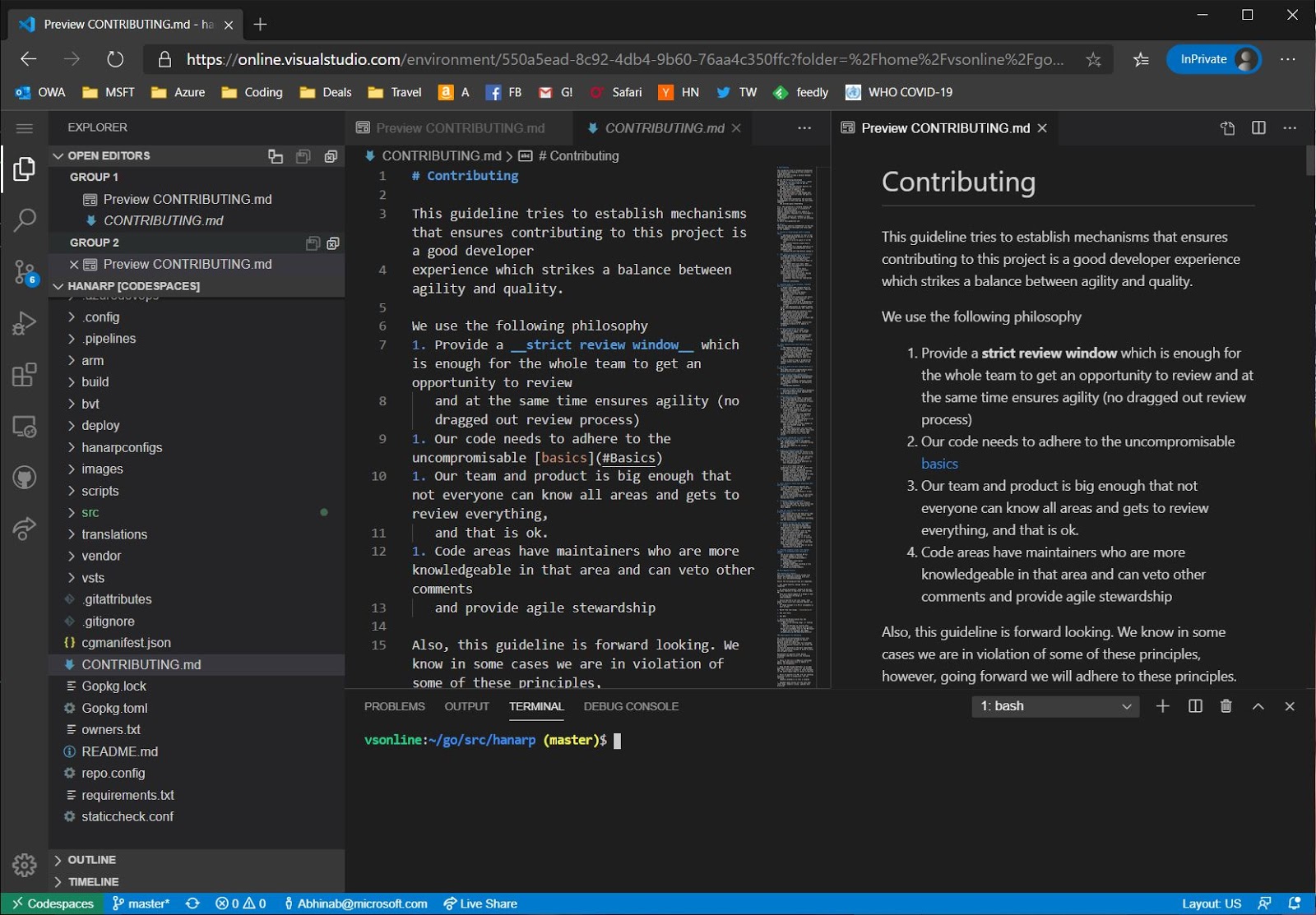
While just being able to use the IDE on our code base is cool in itself, having access to the shell underneath is even cooler. Hit Ctrl+` in vscode to bring up the terminal window.

I then sync'd my linux development environment from https://github.com/abhinababasu/share, installed required packages that I need. Finally I have a full shell and IDE in the cloud, just the way I want it.
To try out Codespaces head to https://aka.ms/vso-login
































![clip_image001[7]](https://lh3.googleusercontent.com/blogger_img_proxy/AEn0k_tR21Y4LjisRDPsszBqevr5CDIXF6Tisv4vBdR4ktQqhpvJp_8RPGr4NnpY7HuHea_rCb9Vm-Ul8JTgyW2K1LHpwhbRFzCzCGxGu5IqraVh6a--ubPqGxRpzbEzG_ry4L22wqjxYxH_3S3VdWBAxkQtoAB799AODgm9QM69e6GMRFUOah1mc5oWcOlSXA84lNOREeLYFjnzqM_L6CykaZ8k26QqJJfh4x8yX9DX9Yg6PGB_3cRkRQtxTGlWCeMPIQA_2N5tQ104kRKwxQ=s0-d)
![clip_image002[7]](https://lh3.googleusercontent.com/blogger_img_proxy/AEn0k_vkteSLe50JcEB0ChnbX9xEkqMm1xgftLW57d2PQm7oWC-qS38vVdrsFmoT-rxFVyX7SsAVEKVep150gT-VKkChDLZ3rkpGvZ1FwOjXf_uArgfxL-3dskW7aU6wwkZ3p2z3V6lBLN5Q4ewuRzPaE9HqvjvNuet6bNFEXMmkU6UawSa23aUiV32UYaiFmHkLmEi4qBKVuHct6F1DTxs1YspG4iDdPdPyk4QuLrt-RY6cyM_OY9pMuIJfmaS0UI1XtwpJdMxKO7IBrmXfGg=s0-d)
![clip_image003[7]](https://lh3.googleusercontent.com/blogger_img_proxy/AEn0k_u7_KuBI5laKlL6xYqNdF9nhS7N6x3Rx433PzeYoB3JG472bmldwUaTMeywebaGHaua5L3tVr6V-9_soZP93YJoe9T1tI1XPbIsegXPBBd3bZkt3rO0sT-CYYuE2pRk9Os1ZtnBcUvBAfle5RJFAB-_ygUaVOgBlqC8Dj-zLzwC6pbgiI_8TTOB5gSNL96OGYZayztcMv2leSSEvzXBRX-Qj6EV-4Un83kPe9TtyXINjezPjDvOHRZWyooSZY0jg0tscj8QqoU2W5wMFg=s0-d)










