In this post I give a brief overview of how we run the control plane of BareMetal Compute in Azure that powers the SAP HANA Large instances (in memory database running on extreme high memory machines). We support different types of BareMetal blades that go all the way up to 24TB RAM including special memory support like Intel Optane (persistent memory) and unlike Virtual Machines, customer get full access to the BareMetal physical machine with root access but still behind network level security sandboxing.
Few years back when we started the project we faced some daunting challenges. We were trying to get custom build SAP HANA certified bare-metal machines into Azure DCs, fit them in standard Azure racks and then manage them at scale and expose control knobs to customer inside Azure Portal. These are behemoths going up to 24 TB ram and based on size different OEMs were providing us the blades, storage, networking gear and fiber-channel devices.
We quickly realized that most of the native Azure native compute stack will not work because they are built with design assumptions that do not hold for us.
- Azure fleet nodes or blades are built to Microsoft specification and have common denominator management API surface and monitoring, but we were bringing in disparate externally certified HW that did not meet us there
- Our model needed to provide customer with full root access to the bare metal blades and they were not isolated across an hyper-visor
- The allocator and other logic in Azure was not location aware. E.g. We had custom NetApp storage literally placed beside the high memory compute for very low latency, high throughput usage that is required by the SAP HANA in memory databases
- We had storage and networking requirements in terms of uptime, latency and throughput that were not met by standard Azure storage, latency and hence we had to build our own.
- We differed in basic layout from Azure, e.g. our blades do not have any local storage and everything runs off remote storage, we had different NW topology (many HW NICs per blade with very different I/O requirements).
Obviously we had to re-build the full cloud stack but with much more limited resources. Instead of 100s and 1000s of engineers we had a handful. So we set down a few guiding principles
- Be frugal on resourcing
- Rely on external services instead of trying to build in-house
- Design for maintainability
Finally 3 years in, we can see that many of our decisions and designs are holding through the test of time. We have expanded to 10s of regions around the world, added numerous scenarios but at the same time never had to significantly scale our dev resources.
Architecture
While it might seem obvious to lot of people building these kinds of services, it was an unlikely choice for a Microsoft service. Our stack is built on Kubernetes (or rather Azure Kubernetes Service), go-land, fluentd and similar open source software. Also we stand on the shoulder of giants, we did not have to invent many core areas because it comes for free inside Azure, like RBAC, cross region balancing etc.
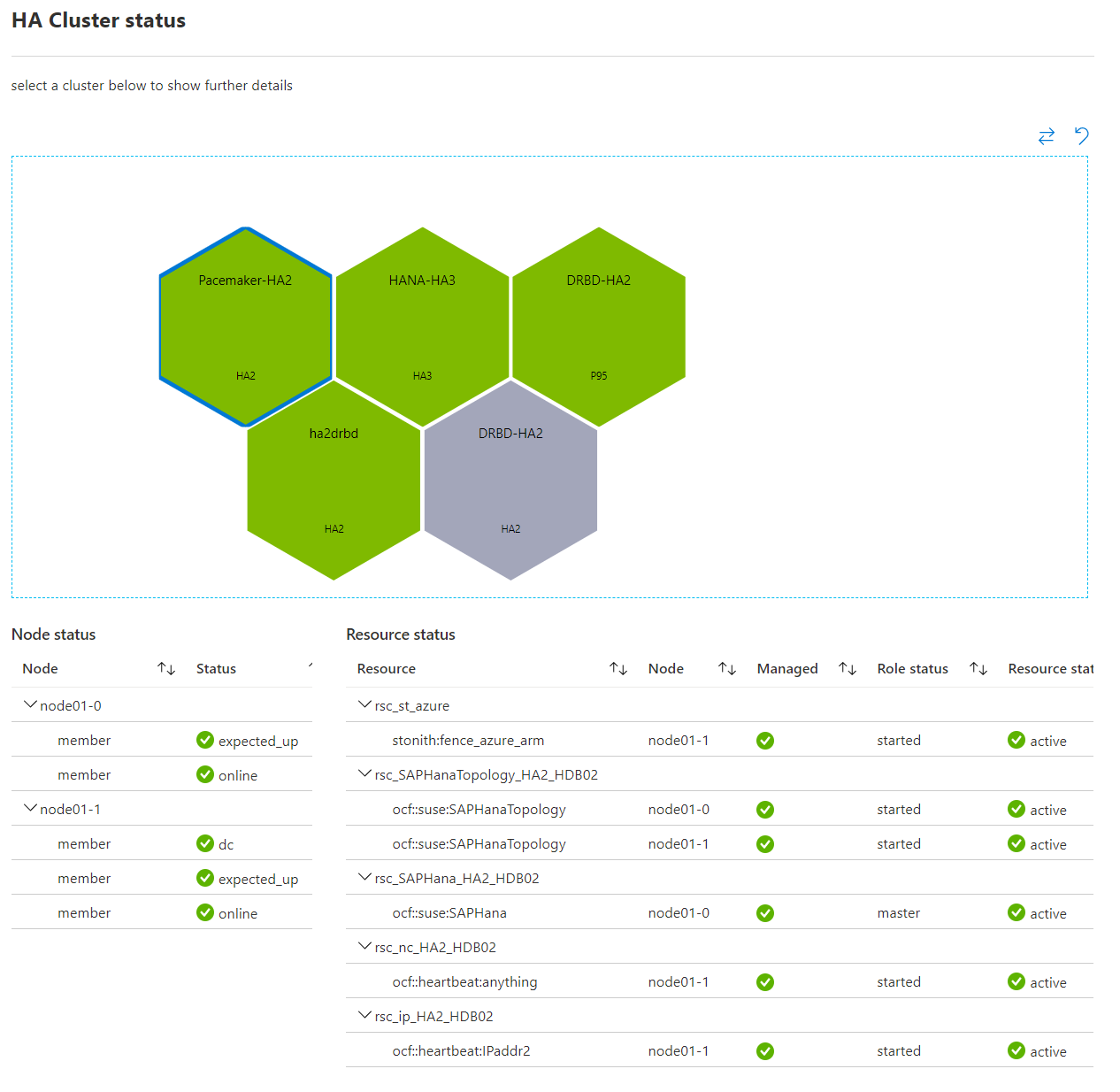
At the high level our architecture looks as follows
Customer Experience
The customer interacts with out system using either the Azure Portal (screenshot above), the command line tools or the SDK. We build extensions to the Azure portal for our product sub-area. All resources in azure is exposed using standardized RESTful APIs. We publish the swagger spec
here and the CLI and SDK is generated out of those.
In any case all interactions of the customer is handled by the central Azure Resource Manager (ARM). It handles authentication, RBAC, etc. Every resource type in Azure is handled by a corresponding resource provider. In our case it is the HANA or BareMetal RP (BmRP). ARM knows (via data the BmRP provides back to it) how to forward calls that it gets from customers to a particular regional instance of BmRP.
The regional Resource Provider or RP
If we are in N Azure regions then the BmRP (resource provider) is deployed in N instances (one in each region) and it runs on Azure Kubernetes Service (AKS). BmRP is build mostly using go-lang and engineered through Azure DevOps. We have automated build pipeline for the RP and single click (maybe a few clicks) deployment. We use use Helm to manage our deployment.
The service itself is stateless and the state is stored in SQL Server Azure. We use both structured data and document-DB style json. All data is replicated remotely to one more region, we configure automated backups for disaster recovery scenarios.
We do not share any state across the RP instances. We are particular about ensuring that every regional instance can completely work on its own. This is to ensure that in case there is a regional outage it does not effect any other regions.
Each instance of RP in turn manages multiple clusters of bare-metal machines. There is one or more such clusters per RP instances. Each cluster is managed by an instance of a cluster manager (CM). All communication between RP and the cluster manager is via two Azure service-bus-queue (SBQ). One from the BmRP to the CM and the other in reverse direction. BmRP issues various commands (JSON messages) to the CM through the SBQ and gets back responses from the CM via the other SBQ.
We pump both metrics (hot-path) and logs (warm path) into our Azure wide internal telemetry pipeline called Jarvis. We then add backend alerts and dashboards on the metrics for near realtime alerting and in some cases also on the logs (using logs-to-metrics). The data is also digested into
Azure Kusto (aka Data Explorer) which is a log analytics platform. The alerts tells us if something has gone wrong (severity two and above alerts ring on-call phones) and then we use the logs in Jarvis or Kusto queries to debug.
Also it's good to call out that all control flow across pods and across the services is encrypted in transit over nginx and linkerd. The data that we store is SQL Server is also obviously encrypted in transit and at rest.
Tech usage: AKS, Kubernetes, linkerd, nginx, helm, linux, Docker, go-lang, Python, Azure Data-explorer, Azure service-bus-queue, Azure SQL Server, Azure DevOps, Azure Container Repository, Azure Key-vault, etc.
Cluster Manager
We have a cluster-manager (CM) per compute cluster. The cluster manager runs on AKS. The AKS vnet is connected over Azure Express Route into the management VLAN for the cluster that contains all our compute, storage and networking devices. All of these devices are in a physical cluster inside Azure Data-center.
We wanted to ensure that the design is such that the cluster manager can be implemented with a lot of versatility and can evolve without dependency on the BmRP. The reason is we imagined one day the cluster-manager could also run inside remote locations (edge sites) and we weren't sure if we can call into the CM from outside or have some other sort of persistent connectivity. So we chose Azure Service Bus Queue for communication using simple json command response going between BmRP and CM. This only requires that the CM can make GET calls on the SBQ end point and nothing more to talk to BmRP.
The cluster manager has two major functions
- Provide a device agnostic control abstraction layer to the RP
- Monitor various devices (compute, storage and NW) in the cluster
Abstraction
Instead of having our BmRP know specifics of all types of HW in the system, it works on an abstraction. It expects basic generic CRUD type of operations being available on those devices and issues generic commands which then the cluster-manager translates to device specific actions.
It is easier to follow through how things work if we take one specific user workflow. Say a customer wants to reboot their BareMetal blade for some reason (an Update category operation). For this the customer hits the reboot button for their blade in Azure Portal, the Portal calls into Azure Resource Manager (ARM). ARM calls into BmRP's REST Api for the same. BmRp drops the reboot blade command into the service bus queue. Finally one of the replica of the cluster-manager container that is listening for those commands pick the command up. Now for various memory sizes and types we use different blades supplied by different OEMs. Some of those blades can be controlled remotely via Redfish APIs, some support ipmi commands, some even proprietary REST apis. The job of the cluster-manager is to take the generic reboot command, identify the exact type of the blade for which the command is and then issue blade specific control commands. It then takes the response and sends it back to the RP as an ack.
Similarly for storage it can handle a get-storage-status command by servicing it with ONTAP (NetApp storage manager) REST Api call .
Telemetry and Monitoring
We use a
fluentd based pipeline for actively monitoring all devices in the cluster. We use active monitoring, which means that not only we listen onto the various events generated by the devices in the cluster, we also call into these devices to get more information.
The devices in our cluster uses various types of event mechanism. We configure these various types of events like syslog, snmp, redfish events to be sent to the load-balancer of the AKS cluster. When one of the fluentd end-points get the event it is send through a series of input plugins. Some of the plugins filter out noisy events we do not care about, some of the plugins call back into the device that generated the event to get more information and augment the event.
Finally the output plugins send the result into our Jarvis telemetry pipeline and other destinations. Many of the plugins we use or have built are open sourced, like
here,
here,
here and
here. Some of the critical event like blade power-state change (reboot) is sent back also through the service-bus-queue to the BmRP so that it can store blade power-state information in our database.
Generally we rely on events being sent from devices to the fluentd end point for monitoring. Since many of these events come over UDP and the telemetry pipeline itself is running on a remote (from the actual devices) AKS cluster we expect some of the events to get dropped. To ensure we have high reliability on these events, we also hence have backup polling. The cluster manager in periodic intervals reaches out to the equipment in the cluster using whatever APIs those equipment support to get their status and fault-state (if any). Between the events and backup polling we have both near real-time as well as reliable coverage.
Whether from events or from polling all telemetry is sent to our Jarvis pipeline. We then have Jarvis alerts configured on these events. E.g. if a thermal event occurs and either storage nodes or blade's temperature goes over a threshold the alert will fire. Same thing for cases like a blade crashing due to HW issues.
Tech-user: AKS, Kubernetes, linux, Docker, fluentd, Ruby, go-lang, Python, Azure service-bus-queue, snmp, ipmi, Redfish, ONTAP, syslog, etc.
Scaling and Reliability
Our front-door is Azure Resource Manager (ARM) through which all users come in. ARM has served us well and provides us with user-authentication, throttling, caching and regional load balancing. It forwards user calls for blades in one region to the RP in that region. So as we add more regions we simply deploy a new instance of the BmRP for that region, register with ARM and scale.
Even in the same region as we land more infra we put them in new clusters with about 100-ish blades and its corresponding storage. Since each cluster has its own cluster manager with a shared nothing model, the cluster manager scales as well along with every cluster we land. As we add more scenarios in the cluster manager though we need to scale the manager itself.
Scaling the cluster manager itself is also trivial in our design, it either gets event traffic from devices or commands from BmRP over SBQ that it then executes. The events come through at the load-balancer of the AKS cluster and hence just increasing the replica count of those containers work. Commands coming from the BmRP arrives over service bus queue and all these containers listen on the same queue, so when we add more replicas of these containers the worker count goes up.
Since we use separate SBQ per CM, adding new CM automatically means new SBQ pair gets created for it. The only concern could be that we add so many new scenarios in the CM that the traffic between one CM and BmRP goes up enough to cause bottleneck in the SBQ. However, SBQ itself can be scaled up to handle it (we have never had to do that), or worst case we may have to add more SBQ, sharding by types of commands and scale it horizontally. To be honest this is not something I think will ever happen.
With all of the above we have been able to meet 99.95 uptime for our control plane and keep latencies under our target. The only place where we hit issues is connectivity with our SQL DB. We had to upscale the DB SKU in the past. We continue to infrequently hit timeouts and other issues at the DB. At one point we were talking about moving to CosmosDB as it is touted to be more reliable, but most likely we will invest in some sort of caching in the future. That can either be by deploying some sort of cache engine in the BmRP itself or most likely use Azure Redis Cache (see principles at the top of this post).